



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
 - Vertical.png){kind=link}
.png){kind=link}
 - Vertical.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
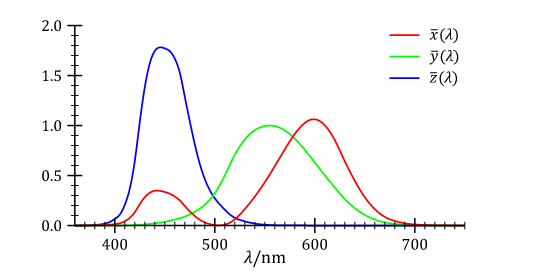{kind=link}
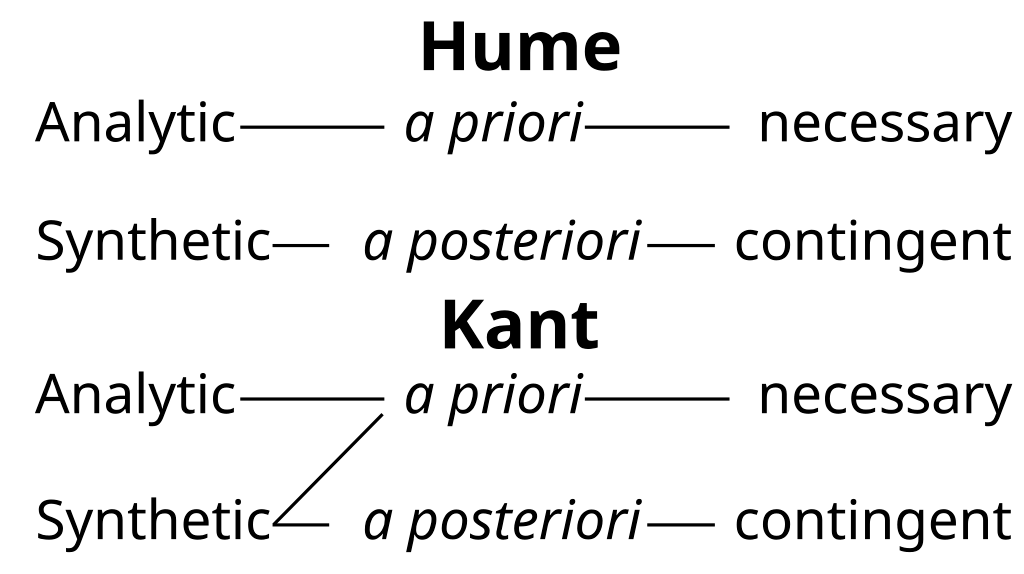{kind=link}
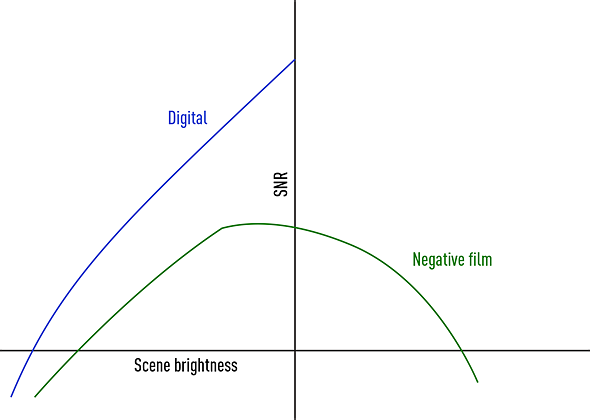{kind=link}
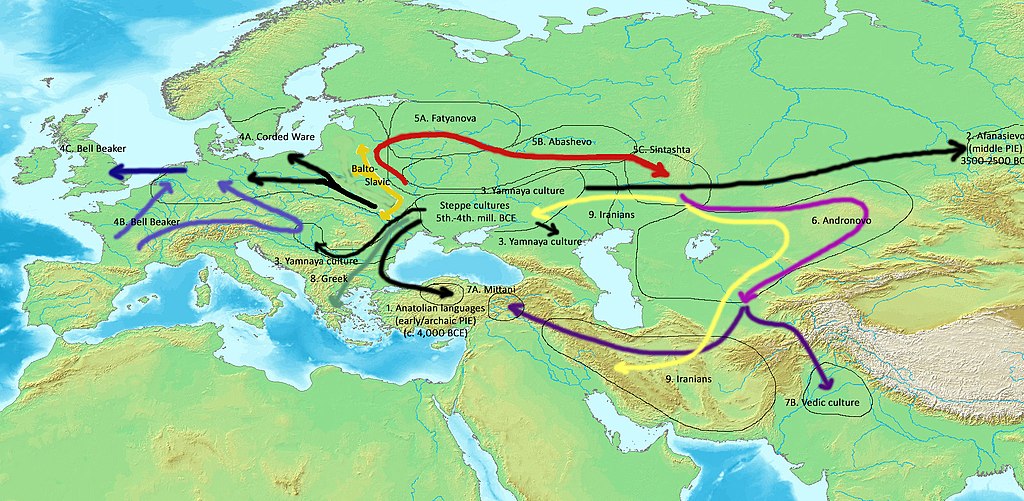{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
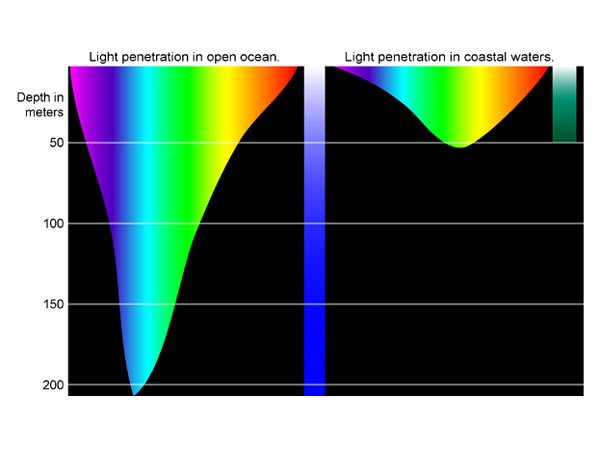{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
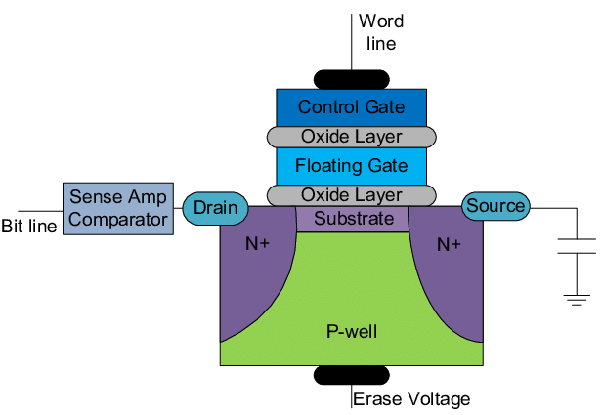{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
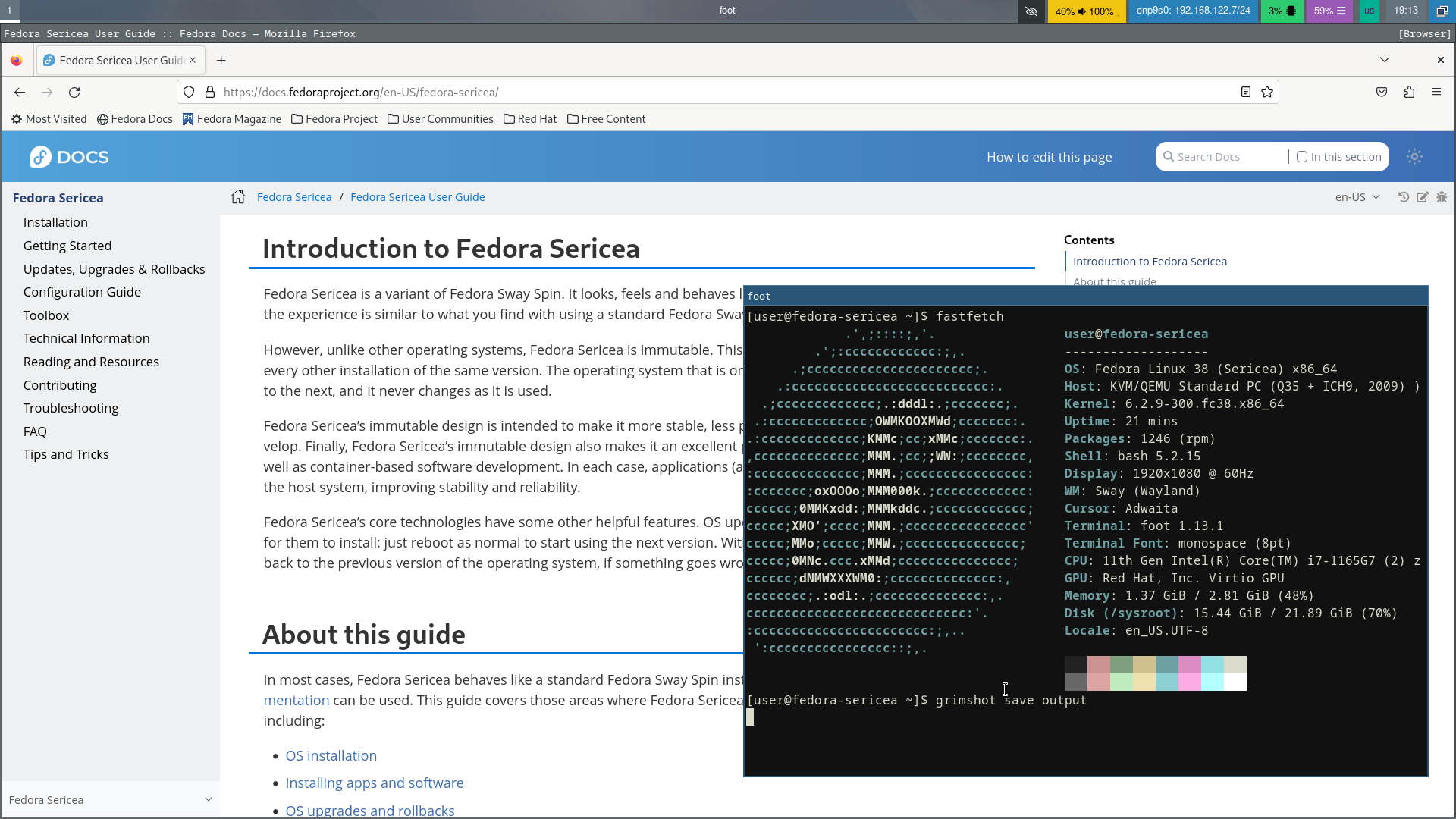{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
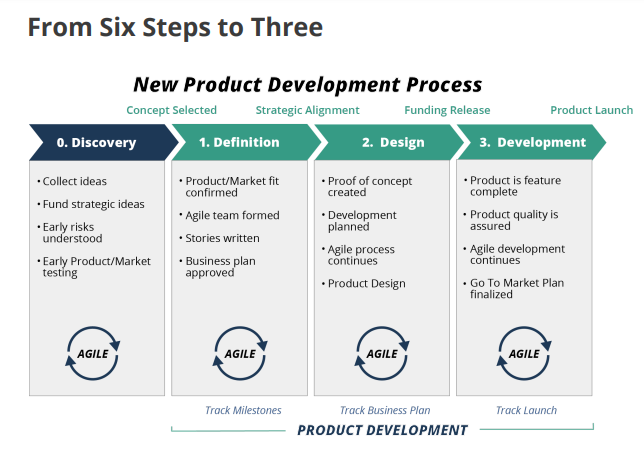
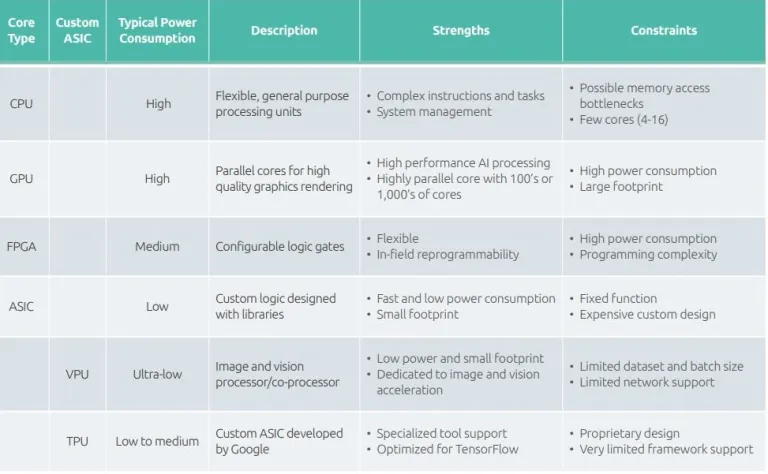
AI Models I Tested
| Hardware | Model | Specifications |
|---|---|---|
| CPU | Intel Pentium Gold 4417U @ 2.3 GHz (Mobile) | 73.6 TFLOPS |
| RAM | 12 GB (4 GB + 8GB) DDR4-SDRAM @ 2400 MHz | 38.4 GB/s |
| ### Template |
## TITLE
- Source: Ollama
- Type: Transformer
- Architecture:
- Format:
- Parameters:
- Bits Per Weight:
- Size:
- Quantization:
- Layers:
- Settings
- Context Width Per Sequence: 2048
- Maximum Sequences: 4
- Total Context Width: 8192
- Attempts
- Attempt 1
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 2
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 3
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 4
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Technical Observations:
-
- Model Specific Observations:
-
TinyLlama 1.1B
- Source: Ollama
- Type: Transformer?
- Architecture: Llama
- Format: GGUF V3
- Parameters: 1.1 Billion
- Bits Per Weight: 4.63
- Size: 606.53 MiB
- Quantization: Q4_0
- Layers: 22
- Settings
- Context Width Per Sequence: 2048
- Maximum Sequences: 4
- Total Context Width: 8192
-
Attempts
- Attempt 1
- Prompt Tokens: 41
- Prompt Tokens/Second: 2.62
- Output Tokens: 75
- Output Tokens/Second: 2.24
- Attempt 2
- Prompt Tokens: 718
- Prompt Tokens/Second: 2.29
- Output Tokens: 143
- Output Tokens/Second: 1.87
- Attempt 3
- Prompt Tokens: 894
- Prompt Tokens/Second: 13.03
- Output Tokens: 144
- Output Tokens/Second: 1.84
- Attempt 4
- Prompt Tokens: 1062
- Prompt Tokens/Second: 11.16
- Output Tokens: 97
- Output Tokens/Second: 1.75
- Attempt 1
-
Technical Observations:
- TinyLlama seems to have about 20 tokens per word. Space character has 24/25 tokens.
- Model Specific Observations:
- So dumb when you ask scientific questions.
Llama-8B Fine-Tuned with DeepSeek-R1
- Source: Ollama
- Type: Transformer
- Architecture: Llama
- Format:
- Parameters: 8.03 Billion
- Bits Per Weight: 4.89
- Size: 4.58 GiB
- Quantization: Q4_K_M
- Layers: 32
- Settings
- Context Width Per Sequence: 2048
- Maximum Sequences: 4
- Total Context Width: 8192 (Trained for 131072)
-
Attempts
- Attempt 1
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 2
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 3
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 4
- Prompt Tokens:
- Prompt Tokens/Second:
- Output Tokens:
- Output Tokens/Second:
- Attempt 1
-
Technical Observations:
-
Model Specific Observations: